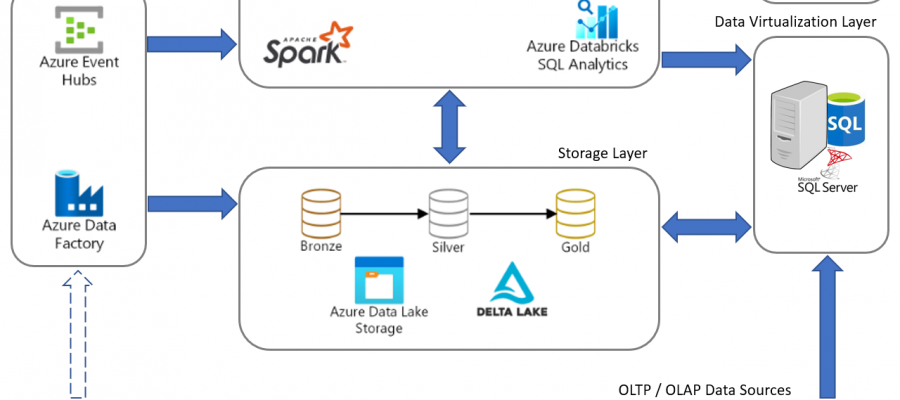
<p>Databricks and SQL Server are both data management technologies, but they serve different purposes and have different strengths and weaknesses.</p>



<p>Databricks is a cloud-based data processing platform that provides a unified analytics engine for data engineering, data science, and machine learning workloads. It&#8217;s designed to handle large-scale data processing using distributed computing technology like Apache Spark. Databricks provides an interactive workspace that allows users to collaborate and analyze data using programming languages like Python, R, and SQL. It also has built-in tools for data visualization and model building.</p>



<p>SQL Server, on the other hand, is a relational database management system (RDBMS) developed by Microsoft. It&#8217;s designed to store, manage, and retrieve data using a structured query language (SQL). SQL Server can handle transaction processing, data warehousing, and business intelligence workloads. It also has built-in tools for data security, backup and recovery, and high availability.</p>



<figure class="wp-block-image size-large"><img src="https://www.thecloudxperts.co.uk/wp-content/uploads/2023/04/fig2-1024x817.png" alt="" class="wp-image-872"/></figure>



<p>The choice between Databricks and SQL Server will depend on your specific data management needs. If you need to process large volumes of data using distributed computing technology, then Databricks may be a better fit. If you need a traditional RDBMS to store and manage data with SQL queries, then SQL Server may be a better option.</p>



<p>However, it&#8217;s important to note that Databricks and SQL Server can work together. For example, you can use Databricks to process and analyze data, and then store the results in SQL Server for long-term storage and querying.</p>



<p><strong>Here&#8217;s a comparison chart between Databricks and SQL Server:</strong></p>



<figure class="wp-block-table"><table><thead><tr><th>Feature</th><th>Databricks</th><th>SQL Server</th></tr></thead><tbody><tr><td>Purpose</td><td>Cloud-based data processing platform</td><td>Relational database management system (RDBMS)</td></tr><tr><td>Workloads</td><td>Data engineering, data science, machine learning</td><td>Transaction processing, data warehousing, business intelligence</td></tr><tr><td>Data Processing</td><td>Distributed computing technology (Apache Spark)</td><td>Relational database technology (SQL)</td></tr><tr><td>Languages</td><td>Python, R, SQL</td><td>SQL, T-SQL, CLR</td></tr><tr><td>Data storage</td><td>Distributed file system (DBFS), cloud storage</td><td>Relational database</td></tr><tr><td>Data Visualization</td><td>Built-in data visualization tools</td><td>Third-party visualization tools</td></tr><tr><td>Security</td><td>Role-based access control, network isolation, encryption</td><td>Active Directory integration, Transparent Data Encryption (TDE)</td></tr><tr><td>Collaboration</td><td>Interactive workspace, version control, collaboration features</td><td>Integration with Visual Studio, team development features</td></tr><tr><td>Cost</td><td>Based on usage and features, can be expensive</td><td>License-based, cost varies based on edition and features</td></tr></tbody></table></figure>



<p>It&#8217;s important to note that this is a general comparison, and the specific features and capabilities of Databricks and SQL Server can vary depending on the edition, version, and deployment model.</p>



<p><strong>Performance Factor</strong></p>



<p>It&#8217;s difficult to create a definitive performance chart comparing Databricks and SQL Server, as their performance can depend on a variety of factors, such as the workload type, data size, hardware resources, and configuration settings. However, here are some general performance characteristics of Databricks and SQL Server:</p>



<figure class="wp-block-table"><table><thead><tr><th>Performance Factor</th><th>Databricks</th><th>SQL Server</th></tr></thead><tbody><tr><td>Data processing speed</td><td>Databricks is optimized for large-scale distributed data processing using Apache Spark, making it well-suited for data engineering and machine learning workloads. It can also handle real-time streaming data using technologies like Structured Streaming.</td><td>SQL Server is optimized for transaction processing and data warehousing workloads. It can handle large volumes of data and complex queries using traditional relational database technology.</td></tr><tr><td>Data storage and retrieval</td><td>Databricks uses a distributed file system (DBFS) and cloud storage for data storage, which can provide high scalability and availability. However, querying data can be slower compared to traditional relational databases.</td><td>SQL Server uses traditional relational database technology for data storage and retrieval, which can provide fast querying performance for structured data.</td></tr><tr><td>Integration with other tools</td><td>Databricks can integrate with a wide range of data science and machine learning tools and libraries, making it easy to create end-to-end data pipelines.</td><td>SQL Server integrates well with other Microsoft technologies, such as Visual Studio and Power BI, and can also work with third-party tools and libraries.</td></tr><tr><td>Hardware requirements</td><td>Databricks is a cloud-based platform and does not require dedicated hardware resources. However, it can benefit from high-performance cloud computing resources, such as GPUs and high-memory instances.</td><td>SQL Server can be deployed on-premises or in the cloud, and can benefit from dedicated hardware resources, such as high-performance storage and processors.</td></tr><tr><td>Cost</td><td>Databricks is a cloud-based platform and charges based on usage and features, which can be expensive for large-scale workloads.</td><td>SQL Server is a licensed software and the cost can vary based on the edition and features required. It can also require dedicated hardware resources, which can add to the overall cost.</td></tr></tbody></table></figure>



<p>Again, it&#8217;s important to note that these are general characteristics and your specific performance results may vary depending on the specific workload and configuration.</p>



<p><strong>Hybrid Solution</strong></p>



<p>A hybrid solution combining Databricks and SQL Server can provide the benefits of both platforms, allowing you to leverage the strengths of each platform for your data management needs. Here are some ways you can use Databricks and SQL Server together:</p>



<ol class="wp-block-list">
<li>Data processing and analysis in Databricks, storage in SQL Server: You can use Databricks for data processing and analysis, and then store the processed data in SQL Server for long-term storage and querying. This can allow you to take advantage of the distributed computing technology in Databricks for large-scale data processing, while still having the benefits of a traditional relational database for querying and managing structured data.</li>



<li>Data preprocessing and feature engineering in Databricks, machine learning model training in SQL Server: You can use Databricks for data preprocessing and feature engineering, and then train machine learning models in SQL Server using the in-database machine learning functionality. This can allow you to take advantage of the scalability and collaborative features of Databricks for data preparation, while still having the benefits of running machine learning models within SQL Server for better performance and scalability.</li>



<li>Real-time streaming data processing in Databricks, storage in SQL Server: You can use Databricks for real-time streaming data processing using technologies like Structured Streaming, and then store the processed data in SQL Server for long-term storage and querying. This can allow you to take advantage of the real-time processing capabilities of Databricks for streaming data, while still having the benefits of a traditional relational database for querying and managing structured data.</li>



<li>Data integration and synchronization between Databricks and SQL Server: You can use data integration tools like Azure Data Factory or Apache NiFi to move data between Databricks and SQL Server, allowing you to create a seamless data pipeline between the two platforms. This can allow you to take advantage of the best features of each platform for different stages of the data pipeline, while still maintaining data consistency and integrity.</li>
</ol>



<p>These are just a few examples of how you can use Databricks and SQL Server together in a hybrid solution. The specific approach will depend on your specific data management needs and the characteristics of your data.</p>



<p><strong>Databricks and PowerBI</strong></p>



<p>A hybrid solution combining Databricks and SQL Server can provide the benefits of both platforms, allowing you to leverage the strengths of each platform for your data management needs. Here are some ways you can use Databricks and SQL Server together:</p>



<ol class="wp-block-list">
<li>Data processing and analysis in Databricks, storage in SQL Server: You can use Databricks for data processing and analysis, and then store the processed data in SQL Server for long-term storage and querying. This can allow you to take advantage of the distributed computing technology in Databricks for large-scale data processing, while still having the benefits of a traditional relational database for querying and managing structured data.</li>



<li>Data preprocessing and feature engineering in Databricks, machine learning model training in SQL Server: You can use Databricks for data preprocessing and feature engineering, and then train machine learning models in SQL Server using the in-database machine learning functionality. This can allow you to take advantage of the scalability and collaborative features of Databricks for data preparation, while still having the benefits of running machine learning models within SQL Server for better performance and scalability.</li>



<li>Real-time streaming data processing in Databricks, storage in SQL Server: You can use Databricks for real-time streaming data processing using technologies like Structured Streaming, and then store the processed data in SQL Server for long-term storage and querying. This can allow you to take advantage of the real-time processing capabilities of Databricks for streaming data, while still having the benefits of a traditional relational database for querying and managing structured data.</li>



<li>Data integration and synchronization between Databricks and SQL Server: You can use data integration tools like Azure Data Factory or Apache NiFi to move data between Databricks and SQL Server, allowing you to create a seamless data pipeline between the two platforms. This can allow you to take advantage of the best features of each platform for different stages of the data pipeline, while still maintaining data consistency and integrity.</li>
</ol>



<p>These are just a few examples of how you can use Databricks and SQL Server together in a hybrid solution. The specific approach will depend on your specific data management needs and the characteristics of your data.</p>